Random Forest
Random forests are an ensemble learning method for classification, regression, and other tasks. They operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or the mean prediction (regression) of the individual trees. Each tree is grown on a random subset of the training data and considers only a random subset of the features at each split, so the forest as a whole corrects for a decision tree’s habit of overfitting its training set: when it is time to make a prediction, the trees vote and the majority wins.
Ensembles are a divide-and-conquer approach to improving performance. The principle behind them is that a group of weak learners can come together to form a strong learner. A weak learner is a model that does only slightly better than random guessing; on its own it is a fair but noisy approximation of the underlying pattern. Average enough of them, however, and their individual errors cancel out as long as they are not all making the same mistake, leaving a far more accurate prediction. That last caveat is the whole game, and it is why decorrelating the trees, discussed below, matters so much.
Decision Trees and Random Forests
A random forest starts with a standard machine-learning technique called a decision tree, which in ensemble terms is our weak learner. An input enters at the root and, as it traverses down the tree, the data is bucketed into smaller and smaller sets by a series of tests on the features; the leaf it lands in determines the prediction. Left unconstrained, a single tree will keep splitting until it memorizes the training set, giving it low bias but high variance.
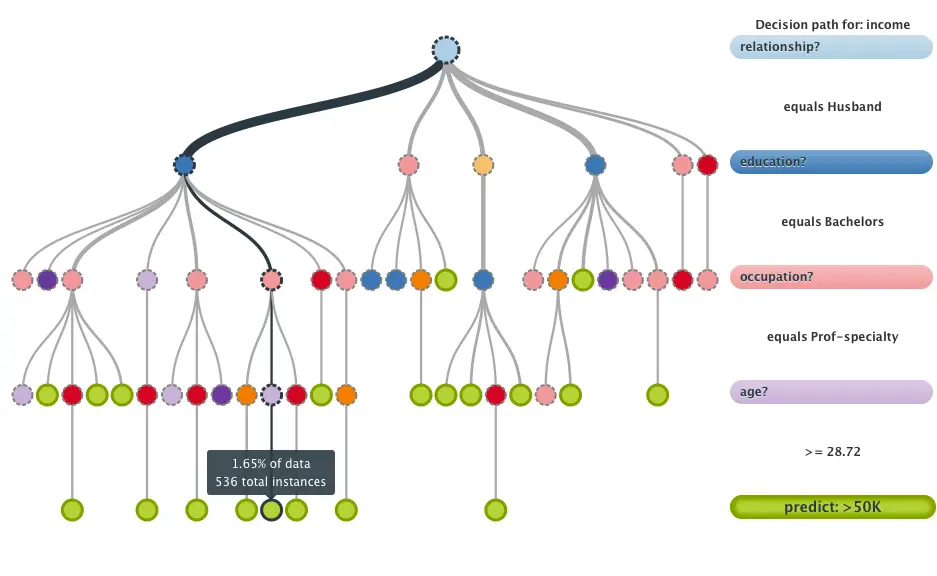
A random forest takes this notion to the next level by training many such trees and letting them vote. In ensemble terms the trees are the weak learners and the forest is the strong learner.
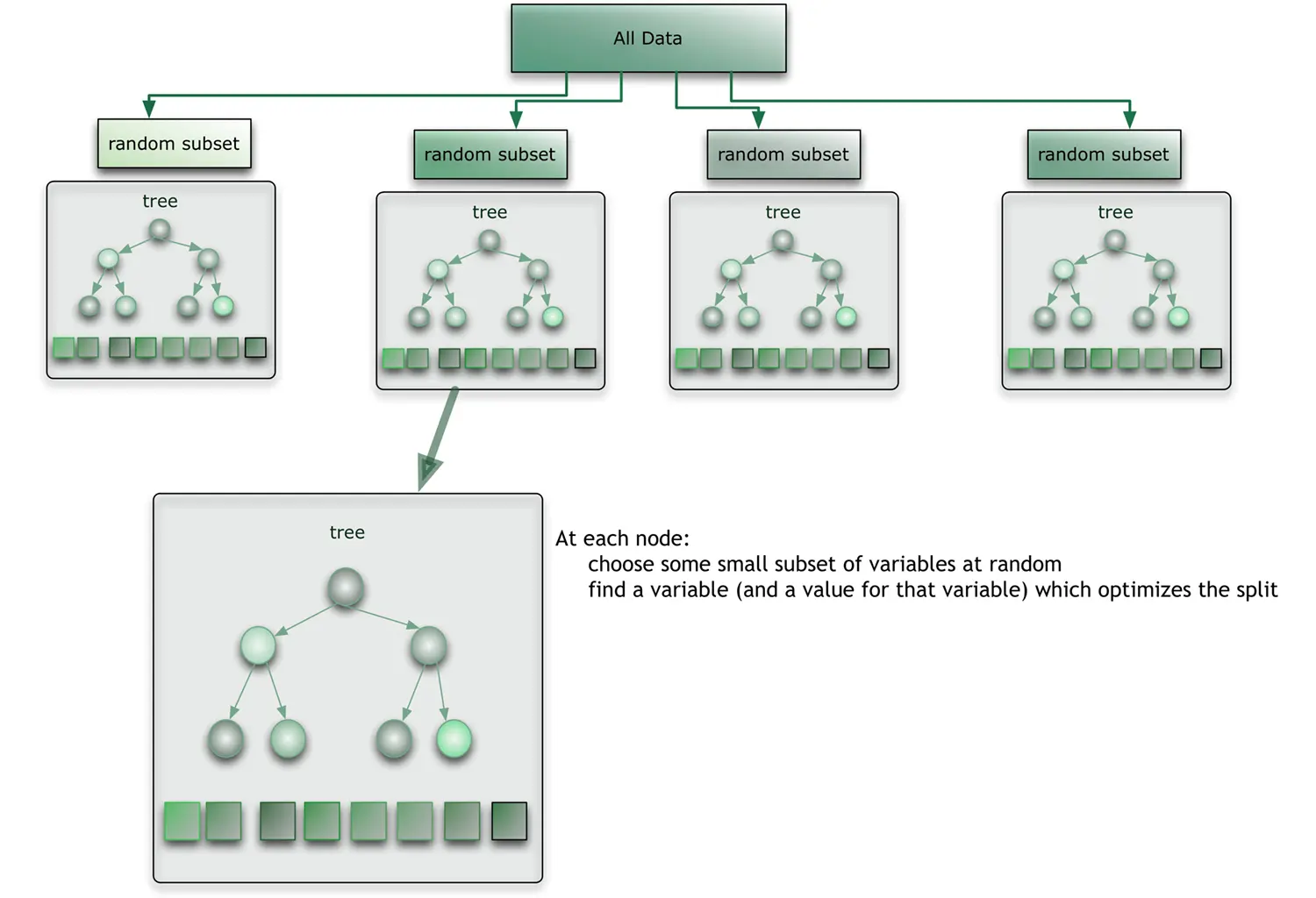
What Makes the Forest “Random”
If every tree were trained on the same data with the same splitting rule, they would all turn out nearly identical, and averaging them would buy nothing. A random forest therefore injects randomness in two independent ways:
- Bootstrap sampling of the rows (bagging). Each tree is trained on a bootstrap sample: a sample of the same size as the original dataset, drawn with replacement. As a result, roughly one-third of the rows are left out of any given tree.
- A random subset of features at each split. Rather than searching every feature for the best split, each node only considers a random subset of them (a common default is $\sqrt{p}$ features for classification, where $p$ is the total number of features).
The second trick is what the word random really refers to. Without it, a handful of dominant predictors would be chosen near the top of almost every tree, making the trees highly correlated, and averaging correlated models barely reduces variance. Forcing each split to ignore most of the features decorrelates the trees, so the variance of the averaged ensemble drops sharply while its bias stays roughly the same.
Out-of-Bag Error and Feature Importance
Because each tree leaves out about a third of the data (its out-of-bag, or OOB, samples), the forest ships with a validation set for free. Every observation can be scored using only the trees that did not see it during training, and the error over those predictions, the OOB error, is an unbiased estimate of the test error. This often makes a separate cross-validation pass unnecessary.
The same machinery yields feature importance. By measuring how much each feature’s splits reduce impurity across the whole forest (or how much accuracy drops when that feature’s values are randomly permuted), a random forest ranks which inputs actually drive its predictions. That interpretability is a big part of why it remains a go-to model for exploratory analysis.
Bagging vs. Boosting
A too-complex model (an unpruned decision tree) has low bias but high variance, whereas a too-simple model (a weak learner such as a decision stump) has high bias but low variance. The two dominant ensemble strategies attack these two failure modes from opposite directions:
- Bagging (Bootstrap Aggregating) targets variance. It builds many independent high-variance models, each on its own bootstrap sample of the data, and averages them. Averaging does not improve any single model’s predictive force, but it narrows the variance toward the expected outcome. Random forest is the canonical example of bagging.
- Boosting targets bias. It trains a sequence of weak models in which each one focuses on the examples its predecessors got wrong, then combines them with a weighted vote. Unlike bagging, the data each model sees is not random; it depends on the errors of the models before it. AdaBoost is the canonical example of boosting.
The Disqus comment system is loading ...
If the message does not appear, please check your Disqus configuration.