AdaBoost
AdaBoost, short for “Adaptive Boosting”, is a machine learning meta-algorithm formulated by Yoav Freund and Robert Schapire who won the Gödel Prize in 2003 for their work. The output of the other learning algorithms (weak learners) is combined into a weighted sum that represents the final output of the boosted classifier.
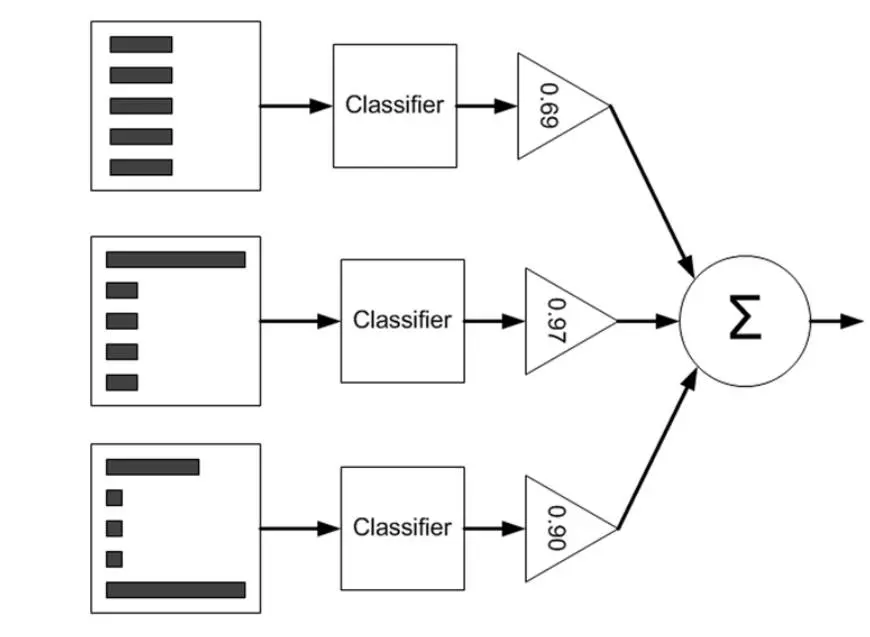
AdaBoost is adaptive in the sense that subsequent weak learners are tweaked in favor of those instances misclassified by previous classifiers. AdaBoost is sensitive to noisy data and outliers and is quite robust to overfitting.
Bagging vs. Boosting
A too complex model (unpruned decision trees) have high variance but low bias whereas a too simple model (Weak learners like decision stumps) have high bias but low variance. To minimize these two types of errors two different approaches are required namely bagging (complex models/high variance) and boosting (simple models/high bias).
- Bagging (stands for Bootstrap Aggregation) is the way decrease the variance of your prediction by generating additional data for training from your original dataset using combinations with repetitions to produce multisets of the same cardinality/size as your original data. By increasing the size of your training set you can’t improve the model predictive force, but just decrease the variance, narrowly tuning the prediction to expected outcome. Random Forest is a typical example of bagging.
- Boosting is a two-step approach, where one first uses subsets of the original data to produce a series of averagely performing models and then “boosts” their performance by combining them together using a particular cost function (=majority vote). Unlike bagging, in the classical boosting the subset creation is not random and depends upon the performance of the previous models: every new subsets contains the elements that were (likely to be) misclassified by previous models. Adaboost is a typical example of boosting.
AdaBoost Algorithm
Given a training set with two classes:
$$\mathbf{T}=\left\{(\mathbf{x}_1, y_1), (\mathbf{x}_2, y_2), \dots, (\mathbf{x}_n, y_n)\right\}$$
where $\mathbf{x}_i \in \mathbb{R}^n$, $y_i \in \left\{-1, +1\right\}$. The procedure of AdaBoost can be described as following:
Input: training set $\mathbf{T}$
Output: the final classifier $G(x)$.
- Initialize weights of training examples: \begin{align}\mathbf{D}_1 = (w_{11}, \dots, w_{1i}, \dots, w_{1n}), w_{1i} = \frac{1}{n}, i = 1, 2, \dots, n\end{align}
- For $m = 1, 2, \dots, M$ (where M is the number of weak classifiers)
- Fit a classifier $G_m(x)$ to the training data using weights $w_i$
- Compute misclassification error of $G_m(x)$:
\begin{align}e_m = P(G_m(\mathbf{x}_i)\ne y_i) =\sum_{i=1}^{n}{w_{mi} I(G_m(\mathbf{x}_i) \ne y_i)}\end{align} - Compute the weight $\alpha_m$ for this classifier $G_m(x)$ \begin{align}\alpha_m = \frac{1}{2}\ln\frac{1 - e_m}{e_m}\end{align}
- Update weights of training examples:
\begin{align}\mathbf{D}_{m+1} = (w_{m+1, 1}, \dots, w_{m+1, i}, \dots, w_{m+1, n})\end{align} \begin{align}w_{m+1, i} = \frac{w_{m, i}}{Z_m} \exp(-\alpha_m y_i G_m(\mathbf{x}_i))\end{align} where $Z_m = \sum_{i=1}^{n}{w_{mi}\exp(-\alpha_m y_i G_m(\mathbf{x}_i))}$ is a regularization term and renormalize to $w_i$ to sum to 1.
- The final classifier $G(x)$ is weighted sum of on each M iterations’ $\alpha$ value and classifier output.\begin{align}G(x) = sign(f(x)) = sign(\sum_{m=1}^{M}{\alpha_m \mathbf{G}_m(x)})\end{align}
$\alpha_m$ stands for the weight of the m-th classifier. According to Equation (2), $\alpha_m \ge 0$ when $e_m \le \frac{1}{2}$. In addition, $\alpha_m$ increase with the decrease of $e_m$. Therefore, the classifiers with lower classification error have higher weights in the final classifier.
Example of AdaBoost
The training examples are given below:
| # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
- Initialize weights of training examples:
$\mathbf{D}_1=(w_{11}, w_{12}, \dots, w_{1 10})$
$w_{1i} = \frac{1}{10}, i = 1, 2, \dots, 10$ - For $m = 1$:
- The misclassification error of the classifier $G_1(\mathbf{x})$ has the minimum value when $v = 2.5$ in training examples with weights $\mathbf{D}_1$
$G_1(\mathbf{x}) = \begin{cases}1, & x<2.5\\-1, & x\ge2.5\end{cases}$ - The misclassification error of $G_1(\mathbf{x})$: $e_1=P(G_1(\mathbf{x_i} \ne y_i))=0.3$
- Compute the weight of the classifier $G_1$: $\alpha_1 = \frac{1}{2} \ln\frac{1 - e_1}{e_1}=0.4236$
- Update the weight of training examples:
$D_2 = (w_21, \dots, w_2i, \dots, w_2 10)$
$w_{2i} = \frac{w_{1i}}{Z_1} \exp(-\alpha_1 y_i G_1(x_i)), i = 1, 2, \dots, 10$
$D_2 = (0.0714, 0.0714, 0.0714, 0.0714, 0.0714, 0.0714, 0.1667, 0.1667, 0.1667, 0.0714)$
$f_1(\mathbf{x}) = 0.4236G_1(\mathbf{x})$ - There’re 3 examples misclassified by the classifier: $\text{sign}[f_1(\mathbf{x})]$.
- The misclassification error of the classifier $G_1(\mathbf{x})$ has the minimum value when $v = 2.5$ in training examples with weights $\mathbf{D}_1$
- For $m = 2$:
- The misclassification error of the classifier $G_2(\mathbf{x})$ has the minimum value when $v = 8.5$ in training examples with weights $\mathbf{D}_2$
$G_1(\mathbf{x}) = \begin{cases}1, & x<8.5\\-1, & x\ge8.5\end{cases}$ - The misclassification error of $G_2(\mathbf{x})$: $e_2=0.2143$
- Compute the weight of the classifier $G_2$: $\alpha_2 = \frac{1}{2} \ln\frac{1 - e_2}{e_2}=0.6496$
- Update the weight of training examples:
$D_3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.1667, 0.1060, 0.1060, 0.1060, 0.0455)$
$f_2(\mathbf{x}) = 0.4236G_1(\mathbf{x}) + 0.6496G_2(\mathbf{x})$ - There’re 3 examples misclassified by the classifier: $\text{sign}[f_2(\mathbf{x})]$.
- The misclassification error of the classifier $G_2(\mathbf{x})$ has the minimum value when $v = 8.5$ in training examples with weights $\mathbf{D}_2$
- For $m = 3$:
- The misclassification error of the classifier $G_3(\mathbf{x})$ has the minimum value when $v = 5.5$ in training examples with weights $\mathbf{D}_3$
$G_1(\mathbf{x}) = \begin{cases}1, & x<5.5\\-1, & x\ge5.5\end{cases}$ - The misclassification error of $G_2(\mathbf{x})$: $e_3=0.1820$
- Compute the weight of the classifier $G_2$: $\alpha_3 = \frac{1}{2} \ln\frac{1 - e_3}{e_3}=0.7514$
- Update the weight of training examples:
$D_4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)$
$f_3(\mathbf{x}) = 0.4236G_1(\mathbf{x}) + 0.6496G_2(\mathbf{x}) + 0.7514G_3(\mathbf{x})$ - All examples can be classifed correctly by the classifier: $\text{sign}[f_3(\mathbf{x})]$.
- The misclassification error of the classifier $G_3(\mathbf{x})$ has the minimum value when $v = 5.5$ in training examples with weights $\mathbf{D}_3$
- The final classifier is $G(\mathbf{x}) = \text{sign}[f_3(\mathbf{x})] = \text{sign}[f_3(\mathbf{x}) = 0.4236G_1(\mathbf{x}) + 0.6496G_2(\mathbf{x}) + 0.7514G_3(\mathbf{x})]$
AdaBoost and Forward Stagewise Modeling
Forward Stagewise Modeling
An additive model can be formulated as follows:
$$ f(x) = \sum_{m=1}^{M} \beta_m b(x; \gamma_m) $$
where $b(x; \gamma_m)$ are the basis functions, $\gamma_m$ and $\beta_m$ are the parameters and weights of the basis functions respectively.
Additive models are fit by minimizing a loss function $L(y, f(x))$ averaged over the training data:
$$ \min_{\{\beta_m, \gamma_m\}_{m=1}^M} \sum_{i=1}^{n} L \left( y_i, \sum_{m=1}^M \beta_m b(x_i; \gamma_m) \right) $$
Directly optimizing such loss function is often difficult. However, if optimizing over one single base function
$$ \min_{\{\beta, \gamma\}} \sum_{i=1}^{n} L \left( y_i, \beta b(x_i; \gamma) \right) $$
can be done efficiently, a simple greedy search method can be used. The basic idea is, sequentially adding new base functions to the expansion function $f(x)$ without changing the parameters that have been added.
The procedure of forward stagewise algorithm is listed below:
Input: Training set $T = \{(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\}$; Loss function: $L(y, f(x))$; basis functions set: $\{b(x; \gamma)\}$$
Output: Additive model $f(x)$$
- Initialize $f_0(x) = 0$$
- For $m = 1, 2, \dots, M$
- Miniminze the loss function
\begin{align} (\beta_m, \gamma_m) = arg\min_{\beta, \gamma} \sum_{i = 1}^{N} L \left( y_i, f_{m-1}(x) + \beta b(x_i; \gamma) \right)\end{align} - Update additive model
\begin{align}f_m(x) = f_{m - 1}(x) + \beta_m b(x; \gamma_m)\end{align}
- Miniminze the loss function
- The additive model can be calculated as \begin{align}f(x) = f_M(x) = \sum_{m=1}^M \beta_m b(x; \gamma_m)\end{align}
AdaBoost Fits an Additive Model
AdaBoost fits an additive model by forward stagewise approach, where
- the base function $b_m$ is a binary classifier $G_m(x): \mathbb{R}^n \rightarrow \{-1, 1\}$;
- the objective function is the exponential loss: $L(y, f(x)) = \exp[-y f(x)]$
First we write down the exponential loss:
$$ (\beta_m, \gamma_m) = arg\min_{\beta, \gamma} \sum_{i = 1}^{N} \exp \left(- y_i ( f_{m-1}(x_i) + \alpha G(x_i)) \right) $$
Then define weights $\omega_i^{(m)} = \exp(- y_i ( f_{m-1}(x_i))$, and divide training data into two subsets: $\{y_i = G(x_i)\}$ and $\{y_i \ne G(x_i)\}$:
$$ \begin{align} G_m^*(x) &= \sum_{i=1}^N \exp[-y_i[f_{m-1}(x_i) + \alpha G(x_i)]] \\ &=\sum_{i=1}^N \omega_i^{(m)} \exp(-y_i \alpha G(x_i)) \\ &=e^{-\alpha}\sum_{y_i = G(x_i)} \omega_i^{(m)} + e^{\alpha}\sum_{y_i \ne G(x_i)} \omega_i^{(m)}\\ &=e^{-\alpha}\sum_{i=1}^N \omega_i^{(m)} + (e^{\alpha} - e^{-\alpha})\sum_{i=1}^N \omega_i^{(m)} I(y_i \ne G(x_i)) \end{align} $$
Then we optimize loss function over $\alpha$
and $G(x)$ iteratively. Once $\alpha$ is fixed, the optimal $G_m^*(x)$ is given by
$$ G_m^*(x) = arg \min_G \sum_{i=1}^N \omega_i^{(m)} I(y_i \ne G(x_i)) $$
In other words, the optimal $G_m^*(x)$ is the classifier that minimizes the weighted prediction error, where $\omega_i^{(m)}$ is viewed as a weight assigned to the i-th training data.
Given a fixed $G_m$, we substitute it into the loss function, take the derivative w.r.t. $\alpha_m$ and set it to zero.
$$ \frac{\partial G_m}{\partial \alpha_m} = \frac{\partial (e^{-\alpha}\sum_{y_i = G(x_i)} \omega_i^{(m)} + e^{\alpha}\sum_{y_i \ne G(x_i)} \omega_i^{(m)})}{\partial \alpha_m} = 0 $$
that is
$$ \begin{align} \alpha_m^* &=\frac{1}{2} \ln \frac{1- e_m}{e_m} \\ e_m &= \frac{\sum_{i = 1}^N \omega_i^{(m)} I(y_i \ne G_m(x_i))}{\sum_{i=1}^N \omega_i^{(m)}} \end{align} $$
References
- Hang Li. Statistical Learning Methods. Tsinghua University Press (2012)
- Freund, Yoav, and Robert E. Schapire. Experiments with a new boosting algorithm. ICML. Vol. 96. 1996.
- https://en.wikipedia.org/wiki/AdaBoost
- http://vivekmishra1991.github.io/blog/2015/09/28/adaboost-why-it-is-robust-to-overfitting/
- http://stats.stackexchange.com/questions/18891/bagging-boosting-and-stacking-in-machine-learning
- https://www.cs.cmu.edu/~epxing/Class/10701-08s/recitation/boosting.pdf
The Disqus comment system is loading ...
If the message does not appear, please check your Disqus configuration.