DynamicVLA
The first VLA model for dynamic object manipulation.
DynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation
Haozhe Xie*, Beichen Wen*, Jiarui Zheng, Zhaoxi Chen, Fangzhou Hong, Haiwen Diao, Ziwei Liu
S-Lab, Nanyang Technological University
visitors arXiv 2601.22153 Stars 🤗 DOM Dataset
TL;DR: DynamicVLA enables open-ended dynamic object manipulation by pairing a compact 0.4B VLM with low-latency Continuous Inference and Latent-aware Action Streaming, evaluated at scale through the new DOM benchmark in both simulation and the real world.

Highlights
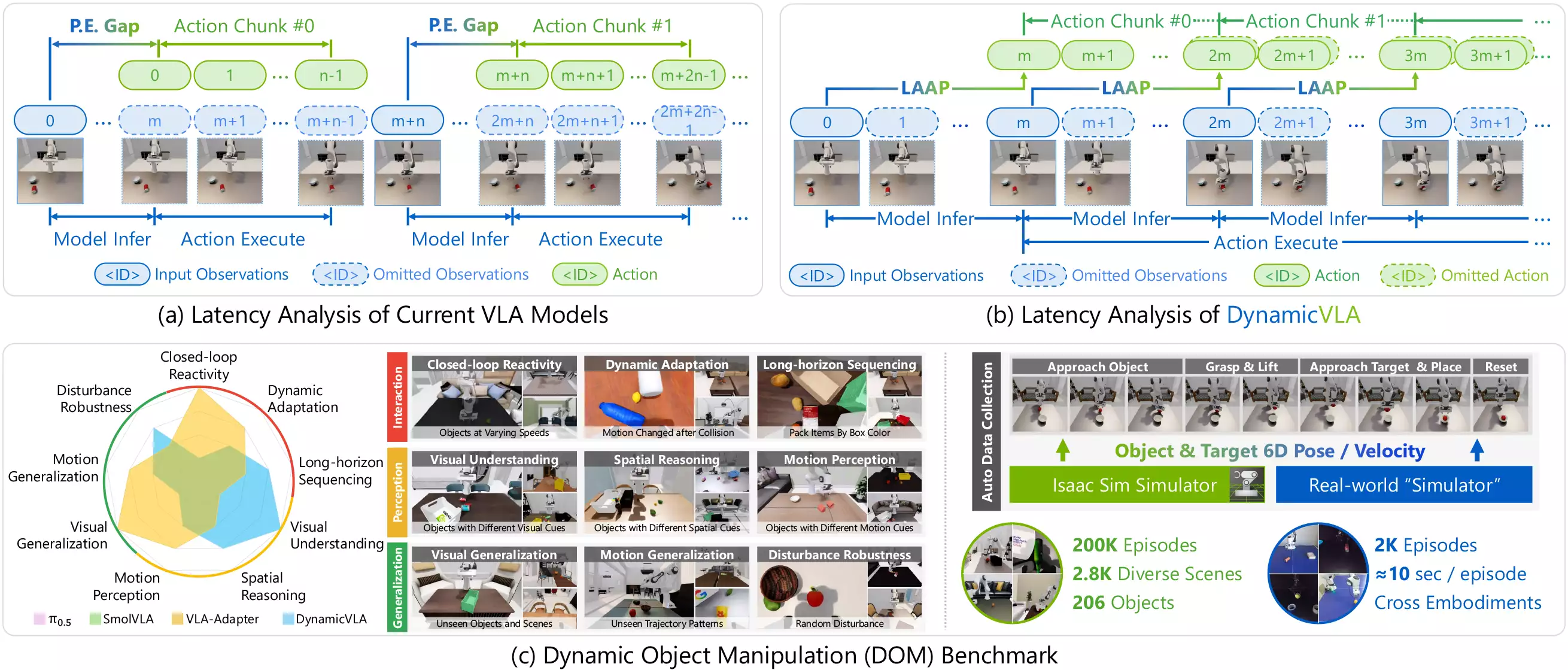
- (a) Current VLA models face perception–execution (P.E.) gaps and inter-chunk waiting, causing delayed reactions to dynamic objects.
- (b) DynamicVLA tackles these challenges with Latent-Aware Action Streaming and Continuous Inference, removing pauses and ensuring seamless action transitions for open-ended dynamic manipulation under high-speed motion.
- (c) The Dynamic Object Manipulation (DOM) benchmark, built from scratch, features 2.8K scenes and 206 objects for evaluating Perception, Interaction, and Generalization, while its auto data collection pipeline enables efficient gathering of 200K synthetic and 2K real-world episodes.
Comparison to the SOTA VLAs
Interaction
Prompt: Pick up the rolling cylinder and place it onto the wooden block.
π 0.5 ❌

SmolVLA ❌

VLASH ❌

DynamicVLA ✅

Prompt: Grasp the rolling roasted sesame container and place it onto the blue frisbee.
π 0.5 ❌

SmolVLA ❌

VLASH ❌

DynamicVLA ✅

Perception
Prompt: Get hold of the moving tennis ball and position it into the paper bowl.
π 0.5 ❌

SmolVLA ❌

VLASH ❌

DynamicVLA ✅

Prompt: Catch the rolling tennis ball and set it within the blue-taped area.
π 0.5 ❌

SmolVLA ❌

VLASH ❌

DynamicVLA ✅

Generalization
Prompt: Grasp the rolling plastic bottle and put it into the wooden box.
π 0.5 ❌

SmolVLA ❌

VLASH ❌

DynamicVLA ✅

Prompt: Pick up the white golf ball and position it inside the red-taped area.
π 0.5 ❌

SmolVLA ❌

VLASH ❌

DynamicVLA ✅

Spotlight Video

Citation
@journal{xie2026dynamicvla,
title = {{DynamicVLA:} A Vision-Language-Action Model for Dynamic Object Manipulation},
author = {Xie, Haozhe and
Wen, Beichen and
Zheng, Jiarui and
Chen, Zhaoxi and
Hong, Fangzhou and
Diao, Haiwen and
Liu, Ziwei},
journal = {arXiv 2601.22153},
year = {2026}
}
Acknowledgments
We thank Prof. David Hsu (NUS) and Prof. Shengping Zhang (HIT) for their support and for providing access to the Franka Emika Panda robot utilized in this work. This work was supported by the Singapore Ministry of Education under its Academic Research Fund Tier 2 (MOE-T2EP20221-0012, MOE-T2EP20223-0002), and by cash and in-kind contributions from NTU S-Lab and industry partner(s).
The Disqus comment system is loading ...
If the message does not appear, please check your Disqus configuration.